Hello there This is @MUB1N
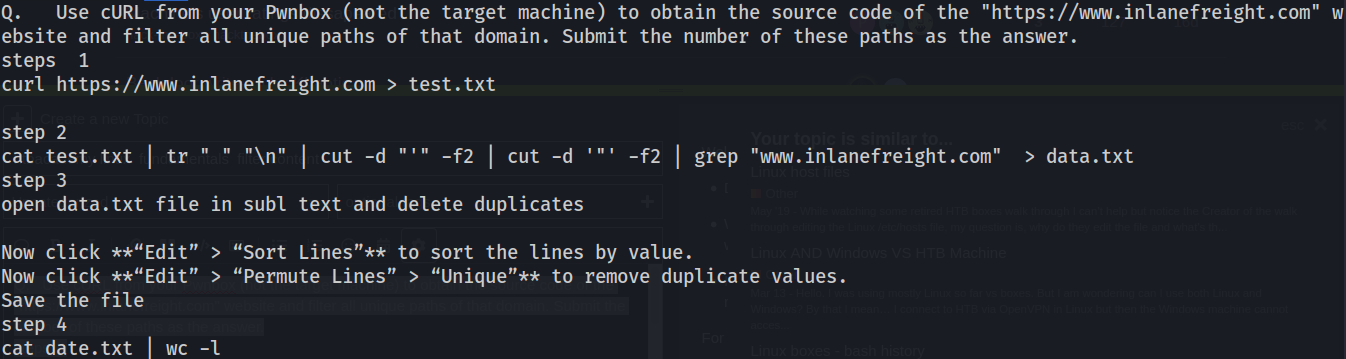
Q. Use cURL from your Pwnbox (not the target machine) to obtain the source code of the “https://www.inlanefreight.com” website and filter all unique paths of that domain. Submit the number of these paths as the answer.
steps 1
curl put given link > test.txt
step 2
cat test.txt | tr " " “\n” | cut -d “'” -f2 | cut -d ‘"’ -f2 | grep “put given link” > data.txt
step 3
open data.txt file in subl text and delete duplicates
Now click “Edit” > “Sort Lines” to sort the lines by value.
Now click “Edit” > “Permute Lines” > “Unique” to remove duplicate values.
Save the file
step 4
cat date.txt | wc -l
ans= 34